Mastering the basics: The Data Engineering Lifecycle
Data Engineering Evolution


Welcome to yet another insightful blog on data engineering. In the previous blogs, I introduced and defined data engineering. Today I am going to walk you through a little bit of history on the evolution of data engineering. Sit back, sip some tea/coffee, and enjoy!
Introduction:
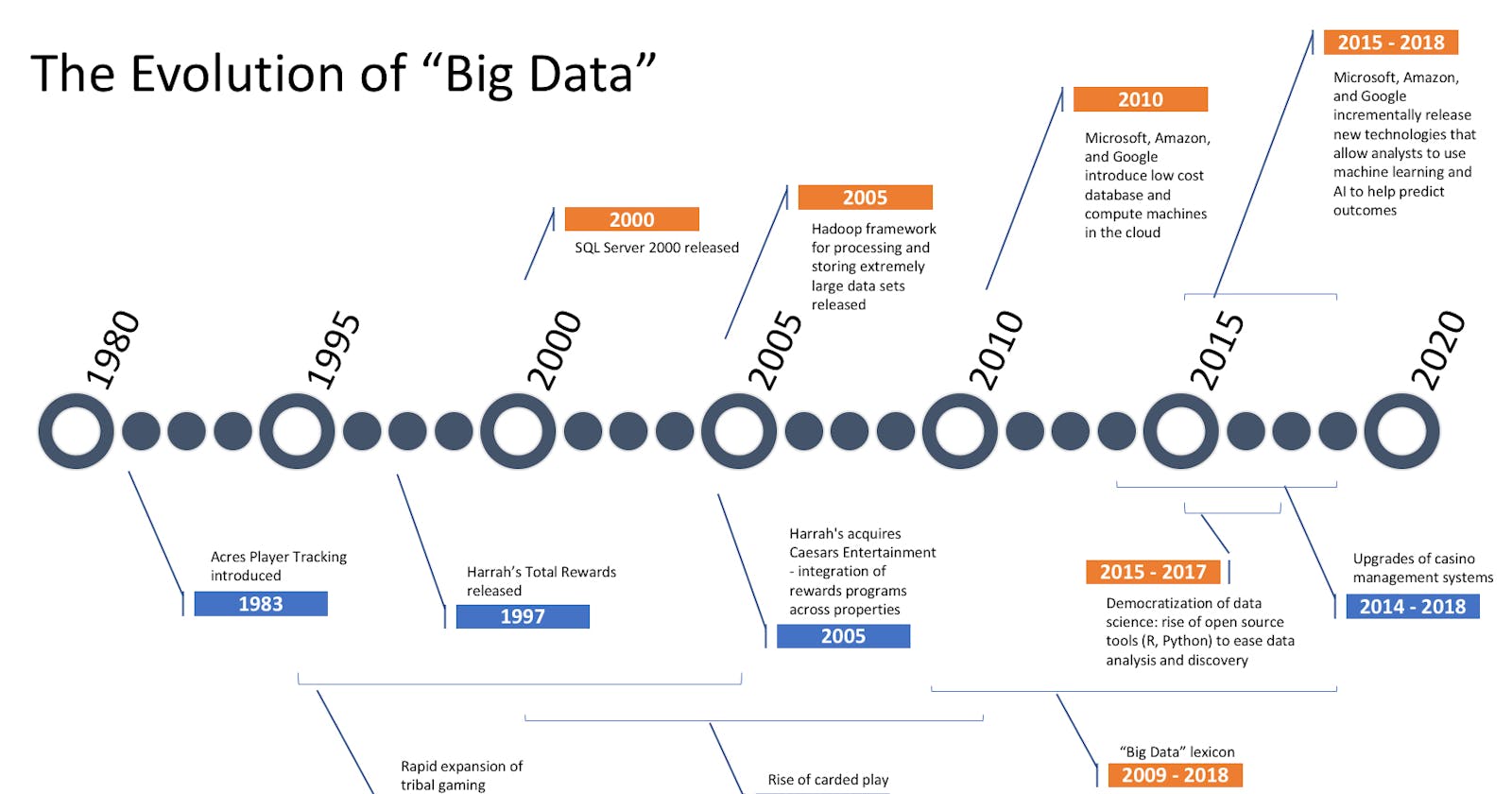
Data engineering has undergone a remarkable evolution since the 1980s, driven by technological advancements and the increasing importance of data in business operations. From the rise of relational databases to the modern era of the data lifecycle, this article traces the significant milestones and shifts that have shaped the field of data engineering over the years.
The 1980s: The Rise of Relational Databases and Data Warehousing:
The 1980s marked a pivotal moment in data engineering with the emergence of relational databases, offering a structured approach to data management. Relational databases introduced a standardized way of storing and retrieving data through the powerful language of SQL (Structured Query Language). During this era, data engineering focused on designing efficient relational database schemas, implementing data models, and building data warehouses. Data warehouses became essential for consolidating and analyzing large volumes of data from multiple sources, enabling businesses to gain valuable insights and make data-driven decisions. The 1980s laid the foundation for the importance of data organization and analytics, setting the stage for future advancements in the field.
The 1990s: The Internet Era and the Emergence of ETL:
The 1990s witnessed the explosion of the internet, ushering in an era of unprecedented data generation. As online platforms and e-commerce websites proliferated, data engineering faced new challenges in managing vast amounts of information. This era saw the emergence of Extract, Transform, and Load (ETL) processes as a critical component of data engineering. ETL became the backbone for extracting data from diverse sources, transforming it into a consistent format, and loading it into data warehouses for analysis. The development of ETL tools and frameworks empowered data engineers to automate complex data integration tasks, ensuring data quality and reliability. The 1990s were a turning point for data engineering, as businesses recognized the importance of data-driven decision-making and invested in robust ETL processes to harness the potential of their growing data assets.

The Early 2000s: The Birth of Contemporary Data Engineering:
The early 2000s marked the birth of contemporary data engineering, as the dot-com bubble burst and surviving companies faced the challenge of managing the exponential growth of data. Traditional monolithic relational databases and data warehouses proved insufficient for the task at hand. This period witnessed the birth of big data engineering, driven by the need for scalable, cost-effective, and reliable solutions. The advent of commodity hardware, which became cheap and widely available, enabled the development of distributed computation and storage on a massive scale. It was during this time that Yahoo, inspired by Google's groundbreaking work, introduced Apache Hadoop. This open-source framework revolutionized large-scale data processing and became the cornerstone of the emerging big data era. Data engineers embraced code-first engineering, leaving behind traditional enterprise-oriented data tools. The shift from batch computing to real-time event streaming further accelerated the data engineering revolution, empowering businesses to process and analyze data in real-time. The early 2000s marked a transformative period in data engineering, where access to bleeding-edge data tools became available to businesses of all sizes.
The 2000s and 2010s: Big Data Engineering:

The subsequent years witnessed the rapid maturation and widespread adoption of open-source big data tools within the Hadoop ecosystem. Silicon Valley's innovation quickly spread across the globe, as companies worldwide gained access to the same cutting-edge data tools used by tech giants. Traditional enterprise-oriented and GUI-based data tools seemed outmoded, and code-first engineering became the new norm with the ascendance of MapReduce. Apache Pig, Apache Hive, Dremel, Apache HBase, Apache Storm, Apache Cassandra, Apache Spark, and Presto were just a few of the technologies that took center stage during this period. However, the term "big data" soon became an overused buzzword, with companies adopting these tools even for relatively small-scale data problems. The realization emerged that data engineering needed to simplify and focus on delivering tangible business insights and value, rather than merely chasing the allure of big data. Despite the challenges, the 2000s and 2010s marked a transformative era in data engineering, as businesses across industries recognized the power of data-driven decision-making and invested in building robust data engineering teams.
The 2020s: Engineering for the Data Lifecycle:
In the current decade, data engineering is rapidly evolving to meet the changing data landscape and business needs. The focus has shifted from managing monolithic frameworks like Hadoop and Spark to adopting decentralized, modularized, managed, and highly abstracted tools. This evolution is driven by the proliferation of data tools, leading to the emergence of the modern data stack—a collection of off-the-shelf open-source and third-party products that simplify data analysis for analysts. With data sources and formats expanding in variety and size, data engineering has become a discipline of interoperation, akin to connecting LEGO bricks to achieve overarching business goals. The contemporary data engineer can be described as a data lifecycle engineer, no longer burdened by the complexities of earlier big data frameworks. While data engineers still possess skills in low-level data programming, their focus has expanded to encompass higher-value activities such as security, data management, DataOps, data architecture, orchestration, and overall data lifecycle management. The 2020s represent a golden age of data lifecycle management, as data engineers have access to better tools and techniques than ever before, enabling them to navigate the complexities of the modern data landscape and unlock the full potential of data for businesses.
The Data Engineering Lifecycle in a Nutshell:
The data engineering lifecycle represents a paradigm shift in how data engineers approach their work. It emphasizes the importance of looking beyond technology and focusing on the data itself, as well as the ultimate goals that the data must serve. The lifecycle consists of five key stages: generation, storage, ingestion, transformation, and serving. Each stage plays a crucial role in the overall data engineering process.
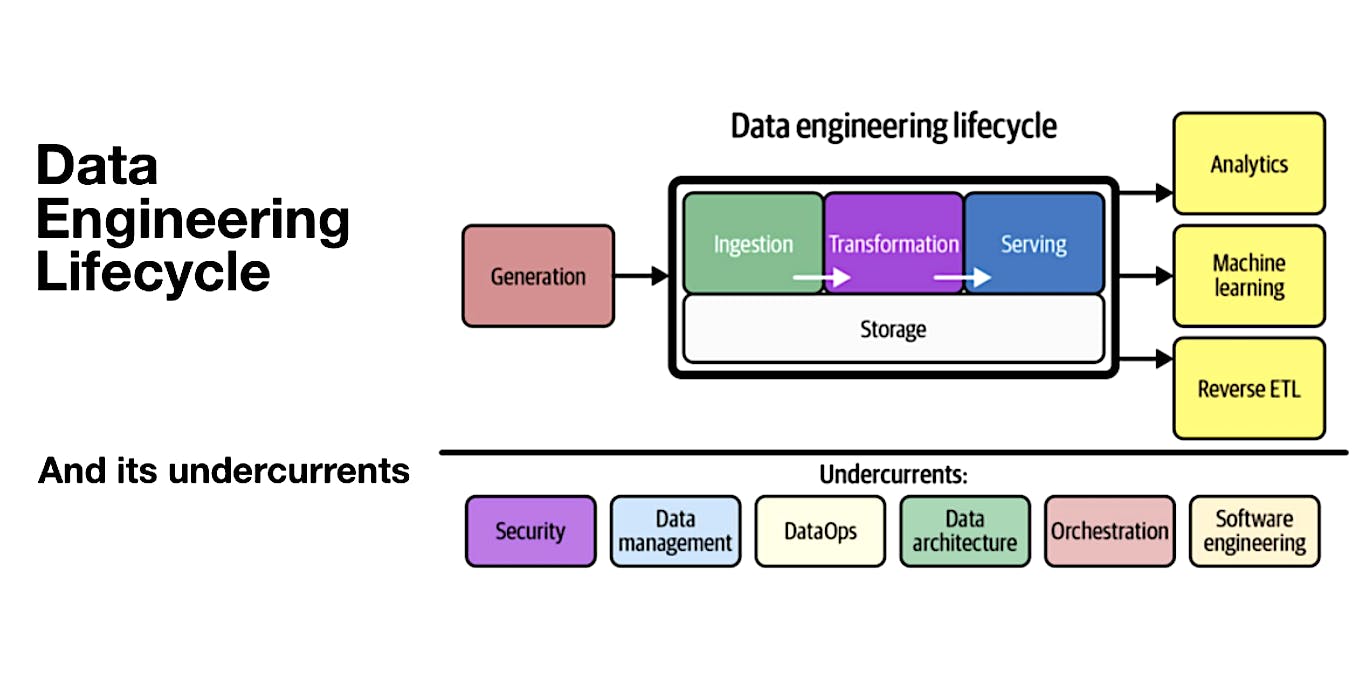
The data engineering lifecycle consists of five key stages: generation, storage, ingestion, transformation, and serving. In the generation stage, data is created or acquired from various sources and collected through sensors, applications, or external vendors. It then moves to the storage stage, where scalable and reliable data repositories are designed and implemented to securely store the data.
After storage, the data progresses to the ingestion stage, where it is extracted from its sources, validated, cleaned, and loaded into appropriate data structures. The transformed data then enters the transformation stage, where it undergoes various processing operations such as cleaning, aggregation, enrichment, and the application of business rules or algorithms. Finally, in the serving stage, the transformed data is made accessible to end users or downstream systems through APIs, data marts, dashboards, or data lakes.
Throughout the data engineering lifecycle, several critical undercurrents ensure its success. Security measures protect the data from unauthorized access or breaches. Data management involves governance practices, data quality assurance, and tracking data lineage. DataOps streamlines and automates workflows for efficient collaboration and deployment. Data architecture focuses on designing the overall infrastructure and integration patterns. Orchestration manages task scheduling and coordination. Software engineering principles are essential for building scalable, reliable, and maintainable data engineering systems. By considering these undercurrents, data engineers can effectively navigate the complexities of the data engineering lifecycle and deliver valuable data products.
Conclusion:
In conclusion, the field of data engineering has undergone significant transformations over the decades, from the early days of manual data processing to the modern era of the data engineering lifecycle. From the emergence of relational databases in the 1980s to the advent of big data technologies in the 2000s and the subsequent shift towards a more modular and managed approach in the 2020s, data engineering has evolved to meet the growing demands of handling vast volumes of data.
The data engineering lifecycle provides a comprehensive framework that encompasses the entire data journey, from its generation to serving actionable insights. By following the stages of generation, storage, ingestion, transformation, and serving, data engineers can effectively manage and process data, enabling organizations to derive valuable insights and make informed decisions. Additionally, the undercurrents of security, data management, DataOps, data architecture, orchestration, and software engineering play vital roles in ensuring the success and efficiency of the data engineering process.
As data continues to grow in size and complexity, the role of data engineers becomes increasingly crucial in harnessing its potential. By embracing the principles and practices of the data engineering lifecycle, data engineers can navigate the ever-changing data landscape and deliver meaningful data solutions that drive business value. The evolution of data engineering has laid the foundation for a data-driven future, where organizations can leverage the power of data to gain a competitive edge and uncover new opportunities.