
Unleashing the power of Data: Understanding Data Creation
Exploring the sources of Data


Introduction
Data is the lifeblood of modern organizations, driving decision-making, insights, and innovation. But have you ever wondered how data is created? In this blog post, we will delve into the various sources of data and explore the ways in which data is generated, both in analog and digital formats. We will also discuss the importance of transactional integrity, logging mechanisms, and the different types of time in data creation processes.
Analog and Digital Data Creation
Data can be created in two primary ways: analog and digital. Analog data is generated in the real world through activities such as vocal speech, sign language, writing on paper, or playing a musical instrument. This type of data is often transient, with its contents lost once the interaction or conversation ends.
On the other hand, digital data is either created by converting analog data into a digital form or is the native output of digital systems. For example, mobile texting apps convert analog speech into digital text, while credit card transactions on e-commerce platforms generate digital data that is saved in databases.
Wide Range of Data Sources
Data is ubiquitous, and it can be captured from various sources in our surroundings. It could come from IoT devices, credit card terminals, telescope sensors, stock trades, websites, mobile applications, and many more. As data engineers or professionals working with data, it is crucial to familiarize ourselves with the source systems that generate data and understand their patterns and quirks.
Understanding Source Systems
To effectively work with data, it is essential to gain knowledge about the source system and its data generation process. This involves reading the documentation of the source system and understanding its operations, such as how it writes, commits, and queries data. For instance, if the source system is a relational database management system (RDBMS), learning its intricacies will greatly impact the data ingestion process.
Main Ideas in Source Systems
In this section, we will explore some of the main ideas related to data creation in source systems.
- Files and Unstructured Data
Files are widely used for data exchange and storage. They can store various types of data, including local parameters, events, logs, images, and audio. Common file formats encountered by data engineers include Excel, CSV, TXT, JSON, and XML, each with its own structure and characteristics.
When dealing with files, it is important to understand their encoding, delimiters, and structure to parse and extract meaningful information. Data engineers often use tools like Python libraries (such as Pandas and NumPy) or dedicated data integration platforms to process and transform file data into a structured format suitable for analysis or storage.
Unstructured data, such as text documents, images, and audio files, also play a significant role in data creation. Extracting insights from unstructured data often involves using techniques like natural language processing (NLP), image recognition, or speech-to-text conversion. These approaches enable the conversion of unstructured data into a structured format that can be analyzed using traditional data processing techniques.
APIs (Application Programming Interfaces)

APIs facilitate data exchange between systems and are commonly used to fetch or send data in a structured format. They provide a set of rules and protocols that enable different software applications to communicate with each other. Understanding APIs and their integration with data systems is crucial for data engineers.
APIs can be categorized into different types, such as REST (Representational State Transfer) and SOAP (Simple Object Access Protocol), each with its own conventions and protocols. When working with APIs, data engineers need to understand authentication mechanisms, data formats (e.g., JSON or XML), endpoints, and rate limits.
Data engineers can utilize APIs to collect data from various sources, such as social media platforms, online services, or external systems. APIs often provide data in a paginated format, requiring pagination techniques to retrieve complete datasets. It is important to be mindful of the limitations and terms of use associated with each API to avoid violations or disruptions.
- Database Systems
Relational databases, such as MySQL, PostgreSQL, or Oracle, are widely used to store structured data in a tabular format. Understanding the schema, tables, relationships, and query language (e.g., SQL) of a database system is crucial for working with the data stored within it.

To capture data from a relational database, data engineers can use database connectors or data integration tools that provide the capability to query and extract data based on specified criteria. These tools enable data engineers to fetch data from specific tables or execute custom queries to retrieve the desired information.
NoSQL databases, such as MongoDB or Cassandra, offer a different approach to data storage and retrieval. They are designed to handle large volumes of unstructured or semi-structured data and provide flexible data models. Data engineers need to understand the data model, query language, and indexing mechanisms specific to the chosen NoSQL database system.
- Streaming Data
Streaming data refers to data that is generated continuously and in real time. It often comes from sources like IoT devices, social media feeds, or online user interactions. Streaming data can be ingested, processed, and analyzed in real time, allowing for immediate insights and actions.
When dealing with streaming data, data engineers must understand the underlying streaming platforms or frameworks. Technologies like Apache Kafka, Apache Flink, or Amazon Kinesis enable the ingestion, processing, and transformation of streaming data at scale. These platforms provide mechanisms for data partitioning, fault tolerance, and processing guarantees, ensuring that the data flow is reliable and resilient.
- Logs, Messages, and Streams
In data creation processes, logging plays a crucial role in recording activities, capturing changes, and providing an audit trail. Logs are records of events or actions that have occurred within a system. They can be textual or structured and contain information about the event, timestamp, and other relevant metadata.
Logs help in troubleshooting issues, analyzing system behavior, and understanding historical patterns. They are commonly used in debugging, performance monitoring, and security analysis.
Messaging systems, such as Apache Kafka or RabbitMQ, provide a means of communication between different components or systems. They facilitate the exchange of data in the form of messages, which can be consumed by multiple subscribers.
Streams, on the other hand, refer to a continuous flow of data records. They are often used in real-time processing and analytics, enabling data engineers to derive immediate insights from streaming data sources. Streaming platforms like Apache Kafka allow for the processing of high-volume data streams and support features like event time processing, windowing, and stateful computations.
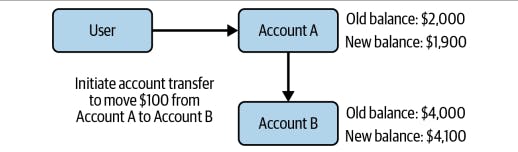
Transactional Integrity: ACID and Atomic Transactions
Maintaining transactional integrity is crucial in data creation processes. ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee reliable and robust database transactions.
Atomicity ensures that a transaction is treated as a single, indivisible unit of work. Either all the changes in a transaction are committed, or none of them are. This property helps maintain data consistency and integrity.
Consistency ensures that a transaction brings the database from one valid state to another. It enforces predefined rules, constraints, and validations to ensure data integrity throughout the transaction.
Isolation ensures that concurrent transactions do not interfere with each other. It guarantees that each transaction is executed as if it were the only one running, preventing data inconsistencies due to concurrent modifications.
Durability ensures that once a transaction is committed, its changes are permanently saved and can survive any system failures. This property guarantees that the data remains intact and recoverable.
Atomic transactions provide a mechanism to group multiple operations into a single logical unit. They ensure that either all the operations in the transaction are completed successfully, or none of them are. This prevents partial updates to the data, maintaining its integrity and consistency.
Types of Time in Data Creation
Time plays a crucial role in data creation, and there are different types of time associated with data:
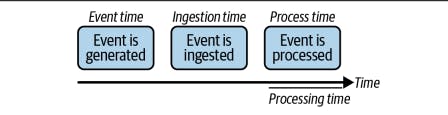
Event Time: Event time is the time at which an event or data point was generated in the real world. It represents the timing as observed in the source system or the original data source. Event time is significant in scenarios where data arrives out of order or has delays due to network latencies or buffering.
Ingestion Time: Ingestion time is the time at which data is ingested into a system or a data pipeline. It represents when the system first receives the data. Ingestion time is often used to track the progress and latency of data ingestion processes.
Processing Time: Processing time is the time at which data is processed or analyzed within a system. It represents the time when a particular computation or transformation is performed on the data. Processing time is useful for measuring the performance and efficiency of data processing workflows.
Conclusion
Understanding the sources of data and the processes involved in data creation is vital for data engineers and professionals working with data. By exploring analog and digital data creation, familiarizing ourselves with source systems, and considering transactional integrity, logging mechanisms, and the types of time associated with data, we can gain a comprehensive understanding of the data creation landscape.
As the world generates more data than ever before, being knowledgeable about the intricacies and nuances of data creation processes will enable us to make informed decisions, derive valuable insights, and unlock the full potential of data-driven solutions.