
Unleashing the power of Data: Choosing the right Storage System
The Data Engineering Lifecycle: Storage


Introduction
Welcome back to my blog series on the data engineering lifecycle; in-depth! In our previous installment, we explored data generation and source systems, laying the foundation for the data lifecycle. In this article, we will delve into the crucial process of selecting a storage solution. Choosing the right storage system is paramount to the success of your data lifecycle. However, it can be a complex undertaking due to the multitude of storage options available and their varying capabilities. In this comprehensive guide, I will discuss key engineering considerations, examine data access frequency, and provide detailed guidance on selecting the most suitable storage system for your specific needs.
The Role of Storage in the Data Engineering Lifecycle
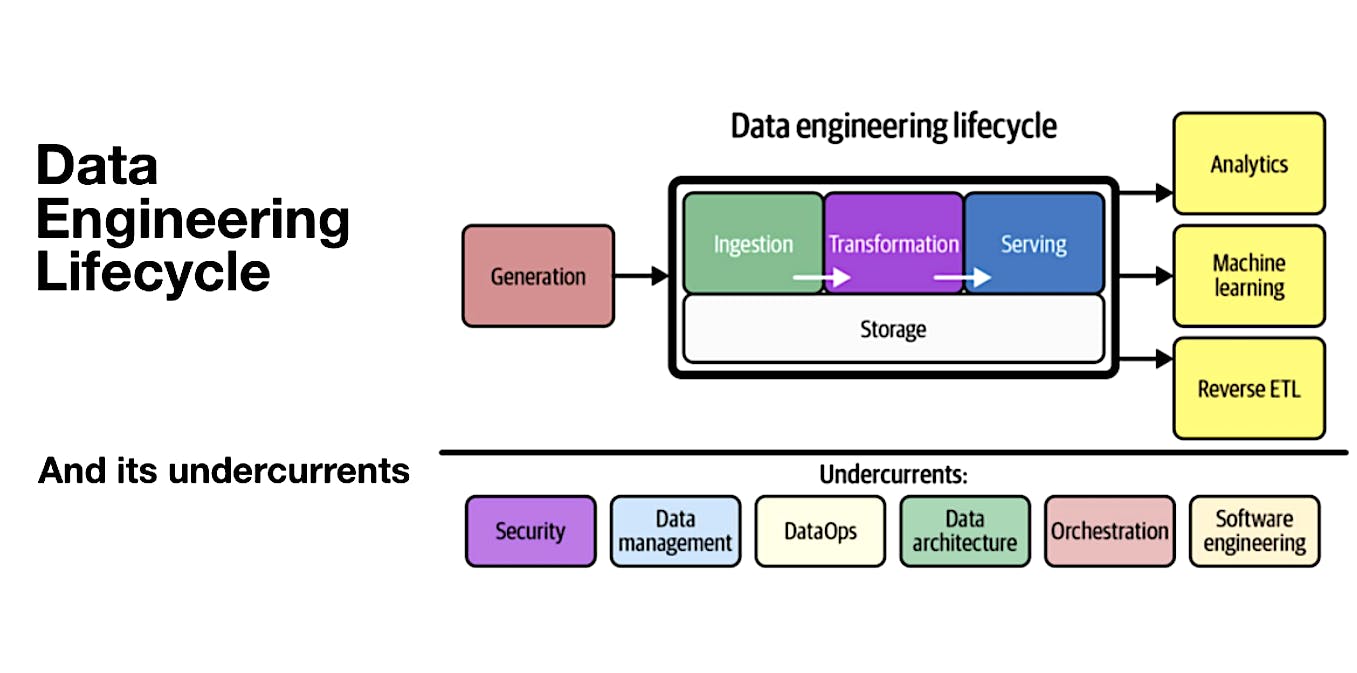
Data storage plays a vital role in the data engineering lifecycle, spanning multiple stages of a data pipeline. It intersects with source systems, ingestion processes, data transformation, and serving mechanisms. The way data is stored significantly impacts its utilization across all stages of the lifecycle. For example, cloud data warehouses can store, process, and serve data to analysts, while streaming frameworks like Apache Kafka and Pulsar serve as ingestion, storage, and query systems. Object storage acts as a standard layer for data transmission. Understanding the role and implications of storage is essential for building robust and efficient data pipelines.
Key Engineering Considerations for Storage System Evaluation
When evaluating storage systems for your data warehouse, data lakehouse, database, or object storage, several engineering questions should guide your decision-making process:
Compatibility with Required Write and Read Speeds: Ensure that the storage solution can handle the desired performance levels for both write and read operations. This includes evaluating the storage system's throughput and latency capabilities. Consider the expected volume of data ingestion and the responsiveness required for data retrieval.
Avoiding Bottlenecks: Assess whether the storage system might become a bottleneck for downstream processes. Consider factors such as data ingestion rates, concurrent access patterns, and scalability to ensure the system can handle the workload without hindering data processing and analysis. Evaluate the ability of the storage system to handle both batch and real-time data processing requirements.
Utilization and Optimization: Understand how the storage technology works and ensure that you leverage its capabilities optimally. Consider the recommended access patterns, data organization strategies, and data partitioning techniques specific to the chosen storage solution. Avoid applying operations that may lead to performance overhead or inefficiencies. Understand the optimization techniques provided by the storage system, such as indexing, caching, and compression.
Scalability: Evaluate the storage system's capacity limits, including total available storage, read/write operation rates, and anticipated future scalability requirements. Assess whether the storage solution can seamlessly handle increasing data volumes over time without compromising performance or cost-effectiveness. Consider options for horizontal scaling, such as sharding or data partitioning, to accommodate growth.
Service-Level Agreements (SLA): Confirm that the storage system can deliver data retrieval within the required SLA to meet the needs of downstream users and processes. Consider factors such as data availability, durability, and latency requirements. Evaluate the storage system's track record in meeting SLAs and its ability to provide high availability and fault tolerance.
Metadata Management: Capture and maintain metadata about schema evolution, data flows, data lineage, and other relevant information. Effective metadata management enhances data discoverability, facilitates data governance, and streamlines future projects and architectural changes. Evaluate the storage system's metadata capabilities, such as support for schema evolution tracking, data lineage tracking, and integration with metadata management tools.
Query Patterns and Schema: Determine whether a pure storage solution (e.g., object storage) will suffice or if a more complex query pattern support (e.g., cloud data warehouse) is necessary. Consider the flexibility or enforcement of schema based on your requirements. Evaluate the query capabilities of the storage system, such as support for SQL-like queries, indexing options, and compatibility with analytical tools. Consider the ease of data modeling and querying based on the storage system's schema model.
Data Governance: Establish mechanisms for tracking master data, golden records, data quality, and data lineage to ensure proper data governance practices. Evaluate the storage system's ability to integrate with data governance frameworks and tools for comprehensive data management. Consider features such as data encryption, access controls, and audit trails to meet security and compliance standards
Regulatory Compliance and Data Sovereignty: Account for any regulatory or compliance requirements specific to your industry or organization. Ensure the storage solution aligns with data sovereignty regulations, especially concerning geographical storage restrictions. Consider features such as data encryption at rest and in transit, access controls based on roles and permissions, and audit capabilities to meet security and compliance needs.
Understanding Data Access Frequency and Data "Temperatures"
Not all data is accessed equally, leading to the concept of data "temperatures." The frequency at which data is accessed determines its temperature. Consider the following categories:
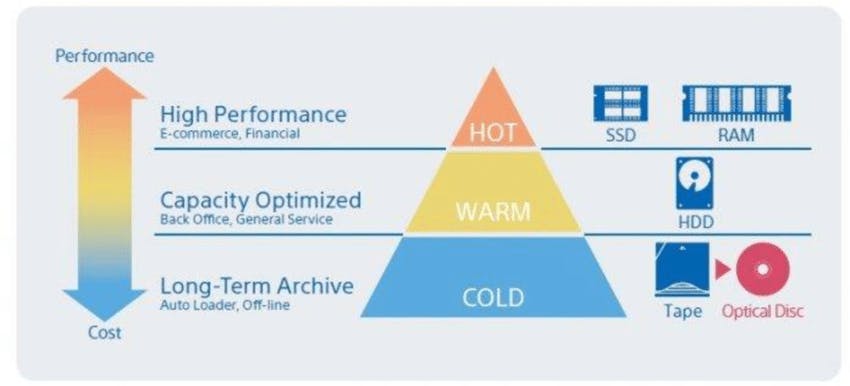
Hot Data: This data is frequently accessed, sometimes multiple times per second, and must be stored for fast retrieval. Examples include systems that serve user requests, where responsiveness is crucial. High-performance storage solutions like in-memory databases or cache systems are often used for hot data to ensure low-latency access.
Warm Data: Warm data is accessed less frequently, typically every week or month, and doesn't require instant retrieval but should still be readily available. Relational databases, data warehouses, or distributed file systems can be suitable for storing warm data. Consider the trade-off between performance and cost when choosing a storage solution for warm data.
Cold Data: Cold data is seldom queried and is often stored for compliance purposes or as a backup in case of catastrophic failures. Cloud providers offer specialized storage tiers for cold data with low monthly storage costs but higher data retrieval fees. Archival systems, tape libraries, or cloud-based cold storage solutions are commonly used for cold data. Evaluate the retrieval costs and retrieval time requirements when selecting a storage solution for cold data.
Selecting the Appropriate Storage System
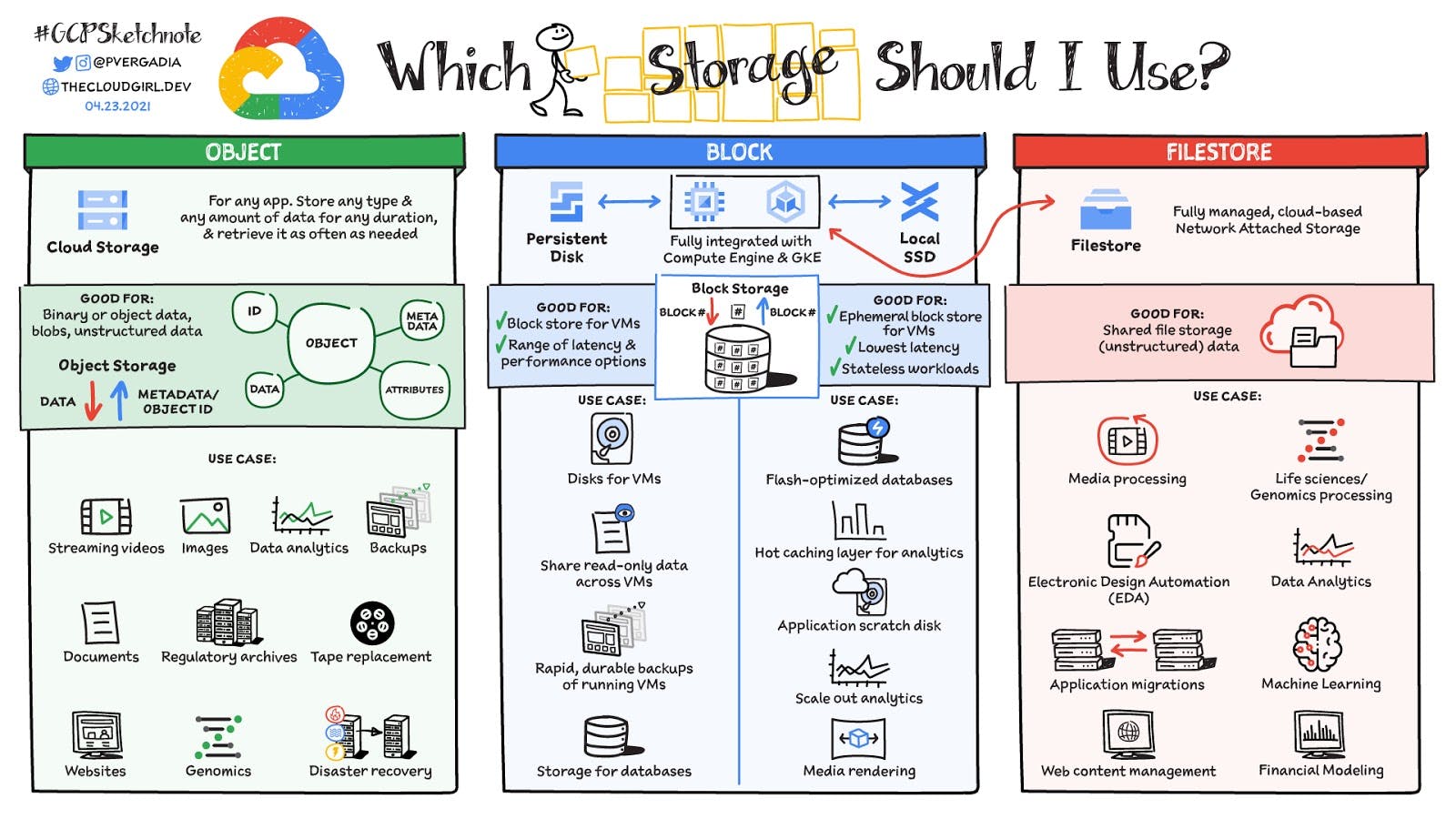
Selecting the right storage solution depends on various factors, including your use cases, data volumes, ingestion frequency, data format, and size. No universal storage recommendation exists, as each technology has its trade-offs. Here are a few popular storage options to consider:
Object Storage: Suitable for storing large amounts of unstructured or semi-structured data. Object storage offers scalability, durability, and cost-effectiveness but may lack complex query capabilities. It is commonly used for data lakes, content repositories, backups, and serving static assets.
Cloud Data Warehouses: Ideal for storing structured or semi-structured data with support for powerful query patterns. Cloud data warehouses provide scalability, performance, and integration with other analytical tools. They are suitable for data analytics, business intelligence, and reporting use cases that require complex querying and aggregation.
Databases: Depending on your needs, different types of databases (relational, NoSQL, and graph databases) can offer the required performance, flexibility, and query capabilities. Relational databases are suitable for structured data with ACID compliance, while NoSQL databases excel at handling unstructured or semi-structured data with high scalability and flexibility. Graph databases are ideal for handling complex relationships and graph-like data structures.
In-Memory Databases and Caches: These solutions are designed for fast, low-latency access to hot data. They store data in memory, providing rapid retrieval times for real-time applications and high-performance workloads
Conclusion
Choosing the right storage solution is a critical decision that significantly impacts the success of your data engineering lifecycle. By evaluating engineering considerations, understanding data access frequency, and selecting the appropriate storage system based on your specific requirements, you can build a robust and efficient data architecture. Remember that there is no one-size-fits-all approach, and careful consideration of trade-offs is necessary to ensure your storage solution aligns with your organization's needs and goals. By making an informed decision and leveraging the right storage solution, you can unlock the full potential of your data and drive meaningful insights and value for your business.